Search
Genome
Metabolism

|
|
Guide to the MetaCyc Database
Contents
2 MetaCyc Overview
3 Position of MetaCyc Within the BioCyc Collection
5 Release Frequency and History
6 MetaCyc Curation
7 Taxonomic Designations for Pathways
10 Comparison of MetaCyc to other Pathway Databases
11 The MetaCyc Team
12 Submitting Pathways for Incorporation into MetaCyc
13 MetaCyc Publications
1 IntroductionThis guide provides additional information on the MetaCyc database (DB) beyond that found in other MetaCyc publications [1, 2, 3, 4, 5, 6, 7], to help users of the database understand its contents in more depth.
2 MetaCyc OverviewMetaCyc is a database of non-redundant, experimentally elucidated metabolic pathways. It stores predominantly qualitative information rather than quantitative data, although we have begun capturing some quantitative data such as enzyme kinetics data. “MetaCyc” is pronounced “met-a-sike”. It sounds like “encyclopedia”. A unique property of MetaCyc is that it is curated[def] from the scientific experimental literature according to an extensive process [6], such that:
2.1 MotivationsThe MetaCyc mission is to serve a broad community of researchers from genetics, molecular biology, microbiology, biochemistry, genomics, bioinformatics, metabolic engineering, and systems biology in support of the following tasks:
2.2 Database ContentsMetaCyc stores pathways involved in:
MetaCyc also stores compounds, proteins, protein complexes and genes associated with these pathways. MetaCyc is extensively linked to other biological databases [8] containing protein and nucleic-acid sequence data, bibliographic data and protein structures. Unlike EcoCyc, MetaCyc provides little genomic data. MetaCyc does contain objects for the genes that encode most of the enzymes within the DB, but MetaCyc contains no sequence data. It does contain links to external sequence databases.
2.3 Query and VisualizationMetaCyc data can be browsed and queried in several different ways. For pathways, proteins, reactions and compounds, the MetaCyc site supports:
Comparison features combine MetaCyc with other BioCyc databases to provide additional ways for viewing data. Examples for Cross-Species comparisons include:
Additionally, a desktop version of the software provides substantially more powerful capabilities. When installed locally with multiple organism-specific databases, the desktop version enables several powerful capabilities, such as:
The desktop version can be downloaded here.
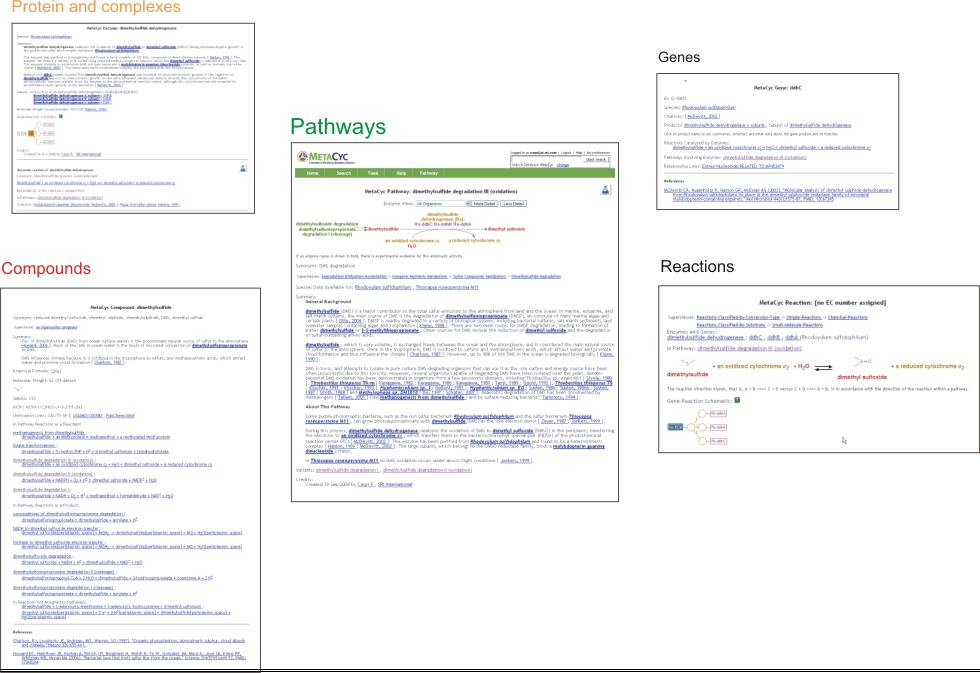
2.4 The MetaCyc Data UniverseMetaCyc inter-relates pathway information (including reactions and their substrates) with genes and their protein products. The diagram below depicts the hyperlinks that are typically available within MetaCyc, allowing the user to navigate among pathways, genes, enzymes, etc.
2.5 Linking to MetaCycUsers are encouraged to link their Web site or application to MetaCyc as described here.
2.6 DevelopmentMetaCyc is a collaborative project between SRI International, the Boyce Thomson Institute for Plant Research, and the Carnegie Institution of Washington. Since its beginning in 1998, MetaCyc’s data have been gathered from a variety of literature and on-line sources. A staff of several full-time curators update MetaCyc on an ongoing basis using a literature-based strategy.[def] [11]
2.7 Underlying SoftwareMetaCyc is based on the same retrieval and visualization software used by EcoCyc and other BioCyc databases - the Pathway Tools platform – which can be obtained here.
3 Position of MetaCyc Within the BioCyc CollectionMetaCyc is a member of the BioCyc collection of Pathway/Genome Databases. In contrast to all other members of that collection, which are organism-specific DBs, MetaCyc is a multiorganism DB. One goal of the MetaCyc project is for MetaCyc to contain a representative example of every experimentally determined metabolic pathway. All other BioCyc databases describe the metabolic network and genome of a single organism, and mix experimentally determined pathways with computationally predicted pathways. MetaCyc does not seek to model the complete metabolism of any particular organism, which is the role of individual BioCyc DBs. Instead, MetaCyc serves as a high-quality reference DB for predicting metabolic pathways in other organisms. Scientists typically use MetaCyc to answer metabolic questions that span multiple domains of life, such as “what are all the pathways for arginine degradation in microbes,” or “what cofactor biosynthesis pathways are known in bacteria?” For questions that require information about the complete genome, proteome, or metabolic network of an organism, instead consult the organism-specific PGDB. For example, MetaCyc contains 14 pathways that have been experimentally studied in Staphylococcus aureus, and 36 enzymes that participate in these pathways. In contrast, the BioCyc Staphylococcus aureus RF122 PGDB contains 189 pathways (most of which are computationally predicted), plus the entire genome and proteome of that strain.
4 MetaCyc AvailabilityMetaCyc is available in several different forms to facilitate different uses of the data:
5 Release Frequency and HistoryNew versions of MetaCyc are released four times per year.
A detailed history of the enhancements to MetaCyc in each MetaCyc release is available here. This page also contains statistics on the size of MetaCyc over time.
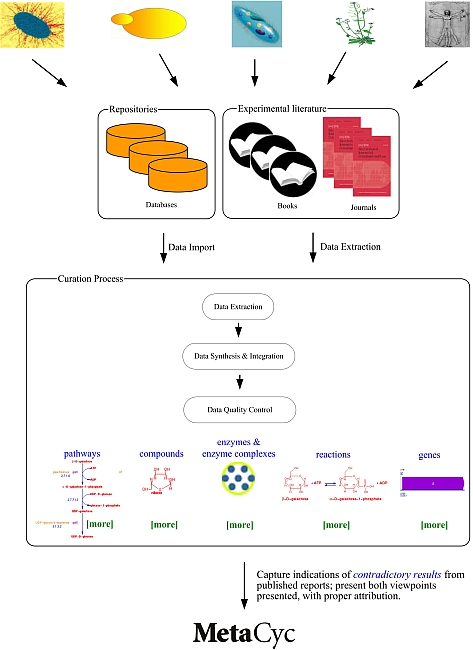
6 MetaCyc CurationCuration is the process of manually refining and updating a bioinformatics database. The MetaCyc project uses a literature-based curation approach in which database contents are extracted in a step-wise manner from evidence in the experimental literature collected from more than 2,000 organisms, as depicted below. The curation procedures that the MetaCyc curators follow are described in the Curator’s Guide to Pathway/Genome Databases. MetaCyc data are derived from primary literature, from reviews, and from external databases. For certain organisms, some of the data within MetaCyc have been directly imported from other databases which we consider to be the authoritative sources of data on those organisms:
6.1 Information Types Captured During the MetaCyc Curation Process6.1.1 PathwaysA summary that includes:
Other data:
6.1.2 Reactions
6.1.3 Enzymes and Enzyme ComplexesA summary that includes:
Other data:
6.1.4 Genes
6.1.5 Compounds
7 Taxonomic Designations for PathwaysMetaCyc contains experimentally elucidated metabolic pathways. Every pathway in MetaCyc is labeled with the name of one or more taxonomic groups in which wet-lab experiments have indicated that the pathway is present. These taxonomic designations include species names, species and strain names, and names of higher taxa such as genus names, e.g., Pseudomonas. When a high-level taxon, such as a genus, is present as a pathway label, the interpretation is that experimental evidence suggests that the pathway is present in all members of that taxon. The “number of organisms” row in the MetaCyc statistics indicates the total number of different organisms that are listed in the taxonomic designations of all MetaCyc pathways. There is wide variation in how many pathways a given taxon contributes to MetaCyc, with some taxa contributing only a single pathway, and other taxa contributing more than 100 pathways. The taxonomic distribution of MetaCyc pathways is summarized here: [Pathway Taxonomic Distribution] . To query MetaCyc pathways by species:
8 Database LinksMetaCyc contains links to many other bioinformatics DBs. Some MetaCyc links are “unification links”, meaning that they are links from an object in MetaCyc to an object in another DB that represents the same biological object. Other links are “relationship links”, meaning that they are links from an object in MetaCyc to an object in another DB that represents a related object, such as a link from a MetaCyc reaction to a PIR protein that catalyzes that reaction. The following types of MetaCyc objects contain links to the following databases.
9 Data SourcesMetaCyc incorporates information that was obtained from the following sources:
10 Comparison of MetaCyc to other Pathway Databases10.1 KEGGKEGG is based on a set of “reference pathway maps.” A KEGG reference pathway map is typically compiled from multiple literature sources, and integrates reactions and pathways found in multiple species. The KEGG web site can display KEGG reference pathways with reactions colored to indicate which enzymes are predicted to be present from a given organism within a reference pathway. We call these diagrams “species views of reference pathways.” The collection of pathways in MetaCyc is analogous to the KEGG reference pathway set, and the organism-specific PGDBs within BioCyc correspond to KEGG species views of reference pathways. MetaCyc Compared to KEGG MetaCyc version 13.5 (2009) contains 1,399 pathways, compared to the 155 pathways in KEGG version 50 (2009). Furthermore MetaCyc assigns more than twice as many of its reactions (4,950 in version 13.5) to pathways as does KEGG (2,463 in version 50). We argue that MetaCyc pathways are closer to true biological pathways than are KEGG pathways. KEGG reference pathways are typically mosaics of related pathways from several different species. KEGG pathways are typically 3-4 times larger than are MetaCyc pathways because MetaCyc pathways attempt to model individual biological pathways from individual organisms. For example, the KEGG pathway called “methionine metabolism” combines pathways for the biosynthesis of methionine, charging of methionyl-tRNA, and conversion of methionine to other compounds such as N-formyl-methionine. The smaller pathways in MetaCyc are advantageous for several reasons. First, these smaller pathways correspond more closely to biologically meaningful units – meaningful in the sense that they correspond to a single biological function, they are regulated as a unit, and they tend to be conserved through evolution. These issues are discussed in more detail in [8], which discusses how these different pathway ontologies can affect computational analyses of pathway data. By defining connected clusters of individual pathways, called superpathways (see the MetaCyc Pathway Ontology)”, MetaCyc does allow the user to view interconnections among several pathways, and to see the larger biochemical context in which a pathway operates. MetaCyc records separately the different pathway variants that have been observed in different organisms; KEGG does not explicitly record pathway variants. Within the large pathways defined by KEGG, it is impossible for the user to tell which subnetworks correspond to distinct biological units, nor in which species these units have been elucidated experimentally. MetaCyc curators author extensive minireview summaries that describe individual pathways and enzymes. KEGG contains no such summaries. MetaCyc cites the primary literature sources from which pathway and enzyme data were obtained. KEGG contains no literature citations, making the sources of KEGG data difficult to ascertain. MetaCyc pathways are labeled with the name(s) of the species in which the presence of those pathways has been experimentally determined, whereas KEGG reference pathways do not state the species in which they were experimentally observed. Pathways in MetaCyc and in other BioCyc PGDBs contain evidence codes that indicate whether experimental or computational evidence supports the presence of the pathway in that organism; KEGG does not use evidence codes. MetaCyc contains data on enzyme properties for specific enzymes from specific species, such as subunit composition, substrate specificity, cofactor requirements, activators, and inhibitors. KEGG has only cofactor data. However, because those data are associated with KEGG reactions rather than with KEGG enzymes, it is difficult to be sure for which proteins from which species the cofactor requirement was experimentally elucidated. BioCyc Organism-Specific PGDBs Compared to KEGG Species Views of Reference Pathways Data that are manually curated from the biological literature by biologist experts are generally preferable to computationally predicted data. Therefore, the curated organism-specific PGDBs in BioCyc, and those created by groups outside SRI for important organisms from Yeast to Arabidopsis, are preferable to KEGG pathway maps that are not curated on an organism-specific basis. PGDBs pathways are edited and customized to reflect species-specific variation of pathways (such as addition or deletion of reactions), whereas KEGG species views of reference pathways do not alter the reference pathways. This approach limits the accuracy of the KEGG species views since all reactions from the reference pathway are always visible, even when known not to occur in a given organism. As of 2006, KEGG contained a large and systematic set of errors in the assignment of enzymes to reactions in its species views of reference pathways. These errors were caused by the improper use of partial EC numbers [[9]. BioCyc contains more than 600 organism-specific PGDBs. Some, such as the EcoCyc DB, have undergone extensive curation. The EcoCyc DB has undergone several person-decades worth of curation, for example. In contrast, it is not at all clear how much curation KEGG organism-specific DBs have undergone. The BioCyc Tier 3 PGDBs are regenerated on an ongoing basis. All BioCyc PGDBs are completely free and open to all users, whereas the KEGG data are not. BioCyc PGDBs are available in easily parsable, regular formats, that are accessible through many different data access mechanisms [3]. Pathway Tools Software Compared to KEGG Software The Pathway Tools software that underlies MetaCyc and BioCyc is much more advanced than the KEGG software in many respects. Pathway Tools can be installed locally at your site, and you can use it to generate pathway predictions at your site. It has a number of other inference tools in addition to its pathway predictor, including a predictor of pathway hole fillers and an operon predictor. It supports painting of omics datasets onto pathway maps.
10.2 UM-BBDThe University of Minnesota Biocatalysis/Biodegradation Database contains (as of March 2008) 197pathways and 870enzymes from 510microorganisms. Pathways are curated from the biomedical literature, and do contain significant comments and literature citations. This database contains information on microbial biocatalytic reactions and biodegradation pathways for primarily xenobiotic, chemical compounds. The goal of the UM-BBD is to provide information on microbial enzyme-catalyzed reactions that are important for biotechnology.
10.3 ReactomeReactome is a curated database of biological processes in humans. It covers biological pathways ranging from the basic processes of metabolism to high-level processes such as hormonal signaling. Reactome information is curated form the literature, and includes significant comments and literature citations. Reactome contains far fewer metabolic pathways than does MetaCyc, and because most Reactome pathways are curated based on human biology, Reactome does not have the taxonomic breadth of MetaCyc, although Reactome pathways have been computationally projected to a number of model organisms.
11 The MetaCyc TeamThis section summarizes the many past and present contributors to the MetaCyc project.
11.1 Current ContributorsRoles: Curation of non plant-related pathways, software development, Web site operations
The Carnegie Institution of Washington Role: Curation of plant-related pathways
Boyce Thomson Institute for Plant Research Role: Curation of plant-related pathways
11.2 MetaCyc Advisory BoardThe MetaCyc Advisory Board advises the project on a variety of matters including task prioritization, database content, user interface issues, and community outreach. The advisors meet once per year. The current board members are listed here.
11.3 Past Contributors
12 Submitting Pathways for Incorporation into MetaCycWe at MetaCyc would like to incorporate pathways created by other scientists into the database. If you are a Pathway Tools user and have created a pathway that fits our criteria, why not send it to us? If we end up including it in MetaCyc, we will credit your contribution in the MetaCyc release notes, and if you wish, your name and your institution will appear on the pathway page. In addition, by submitting pathways to MetaCyc you increase the power of the PathoLogic metabolic-pathway prediction software. PathoLogic recognizes MetaCyc pathways in genome sequence data, and is now in use by more than 100 groups worldwide. If you would like to submit a pathway for inclusion in a future release of MetaCyc, please make sure that you curate the pathway following these guidelines:
For examples of pathways that have been curated based on these guidelines, please see:
Further information can be found in the Curator’s Guide for Pathway/Genome Databases.
12.1 How to Ensure that You and Your Organization Receive the Appropriate CreditPathway Tools includes an author crediting system that can attach author and organization credentials to individual pathways. We recommend that prior to creating new objects in the PGDB you should create an Organization frame for your institute and an Author frame for yourself. This way, items that you create afterwards will be associated with these frames, providing you with the credit that you deserve. This credit information would be retained upon exporting the pathways and importing them into MetaCyc. It is also possible to add credit information to older pathways that were created prior to the creation of your author frame, through the Pathway Info Editor. Detailed instructions on how to create organization and author frames are found in the user manual, in the section ’Creating author frames’.
12.2 How to Send Pathways to MetaCycPathways should be exported into a text file, which can be emailed to us at: . The procedure for exporting a pathways is:
Please indicate if you would like your name and/or affiliation to appear on the pathway and enzyme pages. 13 MetaCyc PublicationsIf you use MetaCyc in your research, we ask that you cite the following publication:
[MetaCyc12] Caspi, R., Altman, T., Dreher, K., Fulcher, C.A., Keseler, I.M., Kothari, A., Krummenacker, M., Latendresse, M., Mueller, L.A., Ong, Q., Paley, S., Pujar, A., Shearer, A., Subhraveti, P., Travers, M., Weerasinghe, D., Zhang, P. and Karp, P.D. (2012)
13.1 Additional Publications
[MetaCyc11] Karp, PD, and Caspi, R.,
A survey of metabolic databases emphasizing the MetaCyc family
label[MetaCyc10]
[MetaCyc10] Caspi, R., Altman, T., Dale, J.M., Dreher, K., Fulcher, C.A., Gilham, F., Kaipa, P., Karthikeyan, A.S., Kothari, A., Krummenacker, M., Latendresse, M., Mueller, L.A., Paley, S., Popescu, L., Pujar, A., Shearer, A., Zhang, P. and Karp, P.D. (2010)
[MetaCyc08] Caspi, R., Foerster, H., Fulcher, C.A., Kaipa, P., Krummenacker, M.,
Latendresse, M., Paley, S., Rhee, S.Y., Shearer, A., Tissier, C.,
Walk, T.C., Zhang, P. and Karp, P.D. (2008)
[MetaCyc06] Caspi, R., Foerster, H., Fulcher, C.A., Hopkinson, R.,
Ingraham, J., Kaipa, P., Krummenacker, M., Paley, S., Pick, J.,
Rhee, S.Y., Tissier, C., Zhang, P. and Karp, P.D. (2006)
[MetaCyc04]
Krieger, C.J., Zhang, P., Mueller, L.A., Wang, A., Paley, S.,
Arnaud, M., Pick, J., Rhee, S.Y., and Karp, P.D. (2004)
[MetaCyc03]
Karp, P.D. (2003)
[MetaCyc02]
Karp, P.D., Riley, M., Paley, S. and Pellegrini-Toole, A. (2002)
[MetaCyc00] Karp, P.D., Riley, M., Saier, M., Paulsen, I.T., Paley, S., and Pellegrini-Toole, A. (2000) See also the BioCyc Publications Page.
14 How to Learn More
References
|