
Guide to the Pathway Tools Schema
Contents
- Introduction
- Slots Valid in Multiple Classes
- Class Compounds
- Class DNA-Binding-Sites
- Class Enzymatic Reactions
- Class Genes
- Class Organisms
- Class Pathways
- Class Polypeptides
- Class Promoters
- Class Complexes
- Class Proteins
- Class Protein-Features
- Class Reactions
- Class Transcription-Units
- Class tRNAs
- Class Regulation
Introduction
All Pathway/Genome Databases (PGDBs) used by the Pathway Tools software -- including the EcoCyc and MetaCyc PGDBs -- must conform to the schema (ontology) described herein. The objects and the relationships between these objects are utilized in this computerized description of metabolic and genomic information. Understanding the schema is essential for both users and developers of Pathway/Genome Databases who are using the Pathway Tools software.In defining a conceptualization of knowledge for computer use, it is essential to employ precise definitions and distinctions. The fidelity of a computer representation determines the degree to which meaningful computations and analyses can be performed with the information in computer form. Unfortunately, many concepts in biology are not defined with the required precision. For example, a half dozen biologists could easily supply a half dozen conflicting definitions for the terms "gene," or "metabolic pathway." You may discover that our definitions of the class names and attribute names employed herein do not match the definitions that you prefer. We ask you to acknowledge that (a) biology is not yet well enough formalized that every biologist can expect to employ the same definitions, and (b) the definitions used in this document are much more thorough and precise (and therefore useful) than those offered in most biological databases.
Much of the discussion in this document refers to the EcoCyc database (DB), but the same schema is used for all other DBs managed by Pathway Tools. This schema may change in future versions of the software.
PGDBs are stored within a frame knowledge representation system (FRS). An FRS is a kind of object-oriented database system. The DB consists of a collection of frames, where each frame encodes information about a single object, such as an enzyme, a gene, or a biochemical pathway.
Instance frames describe specific biological objects, such as a specific gene or a specific metabolic pathway. Class frames describe general types of biological objects, such as the class of all genes. Each frame contains one or more slots. A slot describes an attribute or a property of the object that the frame represents. Each slot makes sense for (is valid in) a particular set of classes. For example, the slot EC-Number makes sense only for frames in the Reactions class, whereas the slot Synonyms is valid in all classes.
The current Pathway Tools ontology contains several hundred classes arranged in a taxonomic hierarchy. Figure 1 shows some of the major classes, and their generalization relationships. An arrow that points from class A to class B indicates that B is a child of A, and therefore that A is a more general class that subsumes B. For example, the class Proteins can be subdivided into the subclasses Polypeptides (monomers) and Protein-Complexes (multimers). Subclasses inherit slots from their parents, for example, Polypeptides inherits all slots defined in Proteins, and some additional slots are also defined in Polypeptides. The classes in this figure whose names are shown in bold are described in more detail in the remainder of this document.
The top-level classes in Figure 1 describe physical entities and processes. More specifically, Chemicals describes atoms and complete chemical compounds, Polymer-Segments describe regions within polymers such as proteins and DNA, and Organisms describes the biological organism modeled within a PGDB. The class Chemicals is subdivided into small-molecular weight compounds (class Compounds) and atoms (not shown), and into macromolecules (Macromolecules). Macromolecules include subclasses such as DNA and RNA; DNA includes subclasses that describe different types of replicons such as chromosomes and plasmids. The different subclasses of Polymer-Segments include different types of DNA sites such as transcription start sites and terminators, and longer regions such as genes. On the process side, Generalized-Reactions describe both individual biochemical reactions, and biochemical pathways. The class Enzymatic-Reactions describes information specific to the pairing of an enzyme with a reaction that the enzyme catalyzes, such as its activators, inhibitors, and cofactors.
Figure 1. Some of the Main Classes Defined in the Schemas of
Pathway/Genome Databases: The arrows denote the
specialization-generalization relationship; for
example, this figure indicates that all polypeptides are
proteins, because class Proteins is the parent (superclass) of
class Polypeptides.
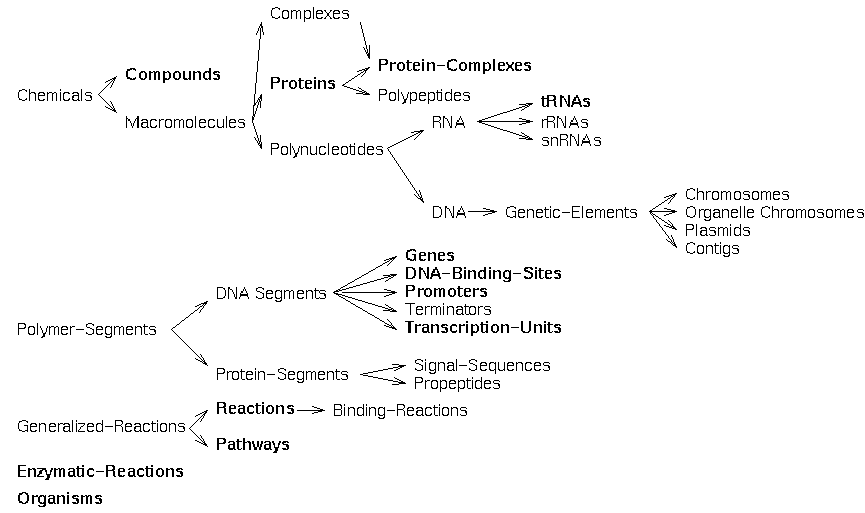 Figure 2 depicts many of the principal relationships among the major
classes in a PGDB. Genome-related classes are green, protein- and regulation-related
classes are orange, and metabolic classes are blue. Arrows indicate relationships among classes,
and the slots that encode those relationships. For example, near the top of the
diagram, the slot Reaction-list encodes the relationship from a pathway to
the set of reactions within that pathway. Slot In-Pathway is the inverse of
Reaction-List, and encodes the relationship from a reaction to the pathway(s)
containing that reaction.
Figure 2 depicts many of the principal relationships among the major
classes in a PGDB. Genome-related classes are green, protein- and regulation-related
classes are orange, and metabolic classes are blue. Arrows indicate relationships among classes,
and the slots that encode those relationships. For example, near the top of the
diagram, the slot Reaction-list encodes the relationship from a pathway to
the set of reactions within that pathway. Slot In-Pathway is the inverse of
Reaction-List, and encodes the relationship from a reaction to the pathway(s)
containing that reaction.
Figure 2. Principal relationships among PGDB classes.
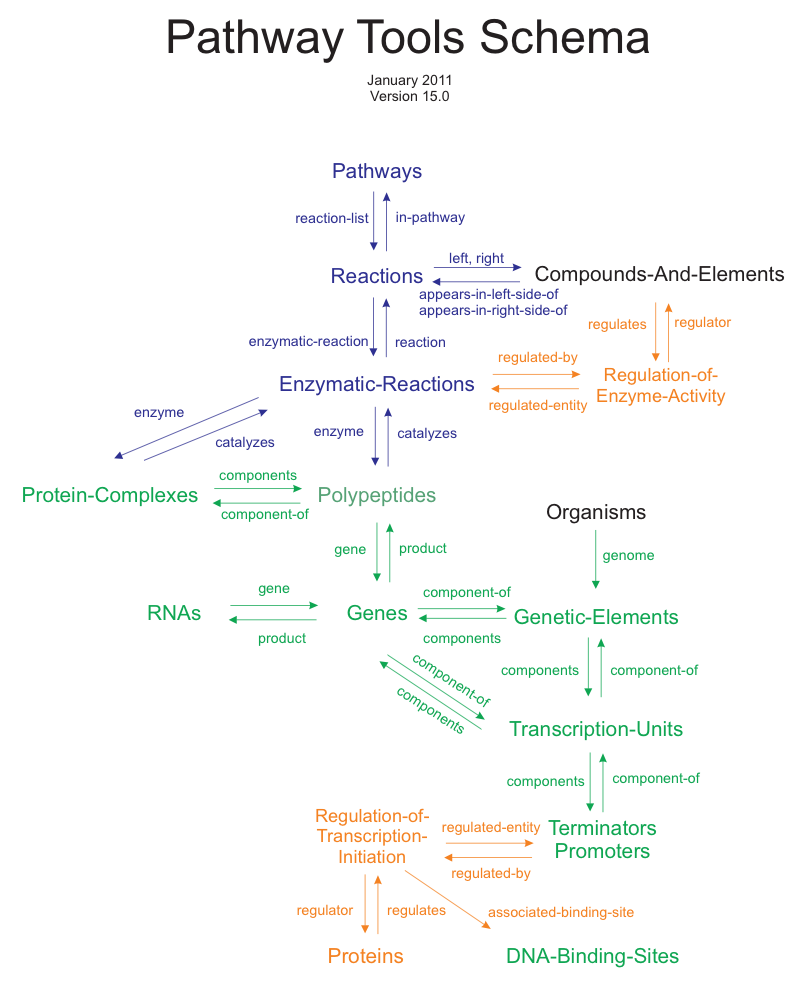
The sections that follow describe the major classes and their slots in more detail. For additional discussions regarding the representations employed in the Pathway Tools ontology, see publications listed at http://BioCyc.org/publications.shtml in the section entitled "Publications on the Pathway Tools Ontology."
Slots Valid in Multiple Classes
In this discussion of slots that are used in several different EcoCyc classes, slot names are sometimes capitalized, and sometimes in lowercase. In fact, all slot names are all uppercase in the database itself. However, for the purpose of writing Lisp queries to Pathway/Genome Databases, all slot names can be written as lowercase because the Lisp interpreter translates all symbol names to uppercase (except for symbol names written between vertical bars). Hyphens separate multiple words in a slot name.Common-Name
This slot defines the primary name by which an object is known to scientists -- a widely used and familiar name (in some cases arbitrary choices must be made). This field can have only one value; that value must be a string.Synonyms
This field defines one or more secondary names for an object -- names that a scientist might attempt to use to retrieve the object. These names may be out of date or ambiguous, but are used to facilitate retrieval -- the Synonyms should include any name that you might use to try to retrieve an object. In a sense, the name "Synonyms" is misleading because the names listed in this slot may not be exactly synonymous with the preferred name of the object.Abbrev-Name
This slot stores an abbreviated name for an object. It is used in some displays.Names
Values of this slot are computed by combining the values of all other name-related slots for this frame: slots Common-Name, Systematic-Name, Synonyms, Abbrev-Name, Accession-1, Accession-2, Last-Name, Middle-Name, First-Name, N-Name, N-1-Name, and N+1-Name.Comment
The Comment slot stores a general comment about the object that contains the slot. The comment should always be enclosed in double quotes.Citations
This slot lists general citations pertaining to the object containing the slot. Citations may or may not have evidence codes attached to them. Each value of the slot is a string of the form [reference-ID] or [reference-id:evidence-code:timestamp:curator:probability:with], where:- reference-ID is a PubMed unique identifier or the identifier of a Publications object (without the leading "PUB-").
- evidence-code is the object identifier of some class belonging to the Evidence class, e.g. EV-EXP.
- timestamp is a lisp universal time (not human readable) corresponding to the time the evidence code was assigned.
- curator is the username of the curator who assigned the evidence code.
- probability is a number between 0 and 1 describing the probability that the evidence is correct, where available.
- with is a free text string that modifies the evidence-code when the citation annotates a GO term. This is the "with" field described in GO documentation.
Examples:
- [123456] -- a PubMed or MEDLINE reference
- [SMITH95] -- a non-PubMed reference
- [123456:EV-IDA] -- an evidence code with associated PubMed reference
- [:EV-HINF] -- an evidence code with no associated reference
- [123456:EV-IGI:9876543:paley] -- a time- and user-stamped evidence code with associated reference
Class Compounds
The Class Compounds describe small-molecular-weight chemical compounds -- typically, compounds that are substrates of metabolic reactions or compounds that activate or inhibit metabolic enzymes.Appears-In-Left-Side-Of, Appears-In-Right-Side-Of
Lists the one or more reactions in which this compound occurs as a reactant or product, respectively.Aromatic-Rings
Each value in this slot is a list of atom numbers; that list of atoms constitutes a single aromatic ring. For example, the list might specify that atoms 1, 2, 5, 6, 10, 20 are in one aromatic ring (see slot Structure-Atoms).Atom-Charges
This slot lists the charges of specific atoms within the compound. Each value of the slot is a list of the form (A C) where A is the index of an atom in slot Structure-Atoms, and C is the charge of that atom.Charge
Lists the chemical charge for this compound.Chemical-Formula
Lists the empirical formula for this compound. Each value of this slot is a list of the form (ATOM COUNT) where ATOM is the ID of a frame for the corresponding chemical element, and COUNT is the number of occurrences of that atom in this compound. For example, molecular oxygen, O2, would be represented as (O 2) with a space between the letter O and the number 2. The value of this slot is computed automatically.Display-Coords-2D
This slot lists coordinates for the display of the chemical structure of this compound in two dimensions. The values of this slot correspond one-to-one to the values of slot Structure-Atoms. Each value of this slot is a list of the form (X Y) and consists of the X-Y display coordinate of the corresponding atom in Structure-Atoms. The coordinates are real numbers with no specified minimum or maximum values. They are rescaled at display time.Gibbs-0
Provides the standard Gibbs free energy of formation of the compound. The values are in units of kilocalories/mol, assuming the common state in aqueous solution at pH=7 and T=25C.InChi
The InChi string for this compound. An InChi (International Chemical Identifier -- see www.inchi.info) is a character string that uniquely identifies a chemical structure. An InChi can be generated by invoking software external to Pathway Tools.Molecular-Weight
Provides the molecular weight of this compound in daltons.N-Name, N-1-Name, N+1-Name
These slots are used when displaying the names of polymeric compounds in pathways that increase or decrease the lengths of the polymers. The names indicate a polymer of length N, length N-1, and length N+1. As an example, see the compound at http://biocyc.org/META/NEW-IMAGE?type=COMPOUND&object=Folatepolyglutamate-n.Regulates
For compounds that have regulatory activity (e.g. as activators or inhibitors of enzymes), this slot points to the Regulation frames that describe the regulation and link to the regulated entity.Smiles
Provides a representation of the chemical structure of this compound using the SMILES chemical encoding system. Note that the value of this slot is computed using an attached procedure; do not attempt to store a value into this slot.Structure-Atoms
This slot is one of several that are used to encode the chemical structure of a compound. This slot lists all the distinct atoms in the compound, with multiple entries for atoms of the same element that occur more than once. For example, water could be described as the list (H H O). The atoms are listed in no special order. However, other slots refer to the atoms in the compound according to their position in this list; for example, the first hydrogen is atom 0, and the oxygen is atom 2.Structure-Bonds
This slot describes the chemical bonds within a compound. Each bond is encoded as a list of the form (A1 A2 B-TYPE) where A1 is the index in slot Structure-Atoms of the first atom in the bond, A1 is the index of the second atom in the bond, and B-TYPE encodes the type of the chemical bond. Valid bond types are the numbers 1, 2, and 3 for single, double, and triple bonds. For example, to specify that a double bond exists between the first and fifth atoms, use the list (1 5 2). (The index-origin is 1.)Class DNA-Binding-Sites
This class describes DNA regions that are binding sites for transcription factors.Abs-Center-Pos
This slot defines the position on the replicon of the center of this binding site.Involved-in-Regulation
This slot links the binding site to a Regulation frame describing the regulatory interaction in which this binding site participates.Site-Length
This slot defines the extent of a binding site in base pairs. If a value for this slot is omitted, the site length will be computed based on the DNA-Footprint-Size of the binding protein. Thus, a value for this slot should only be supplied here if the site length for a particular transcription factor is not consistent across all its sites.Class Enzymatic Reactions
Frames in the class Enzymatic-Reactions describe attributes of an enzyme with respect to a particular reaction. For reactions that are catalyzed by more than one enzyme, or for enzymes that catalyze more than one reaction, multiple Enzymatic-Reactions frames are created, one for each enzyme/reaction pair. For example, Enzymatic-Reactions frames can represent the fact that two enzymes that catalyze the same reaction may be controlled by different activators and inhibitors. See here for more details.Enzyme
This slot lists the enzyme whose activity is described in this frame. More specifically, the value of this slot is the key of a frame from the class Protein-Complexes or Polypeptides.Required-Protein-Complex
Some enzymes catalyze only a particular reaction when they are components of a larger protein complex. For such an enzyme, this slot identifies the particular protein complex of which the enzyme must be a component.Reaction
The value of this slot is the key of a frame from the Reactions class -- the second half of the enzyme/reaction pair that the current frame describes. In fact, this slot can have multiple values, which encode the multiple reactions that one catalytic site of an enzyme catalyzes.Regulated-By
The values of this slot are members of the Regulation class, describing activator or inhibitor compounds for this enzymatic reaction.Cofactors, Prosthetic-Groups
The literature uses terms such as coenzyme, cofactor, and prosthetic group in an extremely inconsistent fashion. In version 2.8 of EcoCyc (March 1996), we adopted the usage of terms that were developed by Evgeni Selkov (Gene Selkov) for use in the Enzymes and Metabolic Pathways (EMP) database.Class Reactions defines the substrates of a reaction as the union of its reactants and its products. After Selkov, we define a coenzyme to be a specialization of substrates, namely, substrates with a relatively stable, conserved moiety, whose main function is group transfer among different enzymes and pathways. Example: NAD. EcoCyc does not define a special slot for coenzymes.
Also after Selkov, we define cofactors and prosthetic groups to be compounds that are required for an enzyme to catalyze a reaction, but that are unchanged by the reaction. Thus, cofactors and prosthetic groups are (loosely speaking) activators of an enzyme in the sense that the enzyme is not active when these compounds are absent. However, cofactors and prosthetic groups have an infinite "activation degree", thus distinguishing them from those compounds that are activators described by Regulation frames listed in the Regulated-By slot; when those activators are missing, the enzyme still functions, but at a lower rate.
The distinction between cofactors and prosthetic groups is that prosthetic groups are covalently or tightly bound to an enzyme, whereas cofactors are not. The corresponding slot names are Cofactors and Prosthetic-Groups.
A slot called Cofactors-Or-Prosthetic-Groups identifies compounds whose binding affinity to the enzyme is unclear.
Alternative-Substrates, Alternative-Cofactors
These slots record variability in the substrates and cofactors that have been observed for this enzymatic reaction. If, for example, the literature indicates that Mn+2 can substitute for Mg+2 as a cofactor in this reaction, we would list the following as a value for the Alternative-Cofactors slot: (Mg+2 Mn+2).The Alternative-Substrates slot describes the substrate specificity of an enzymatic reaction. We use the Alternative-Substrates when the complete equation is not known for an alternative reaction, or when the alternative reaction is not physiologically important, or is not a member of a known pathway. Each value of the Alternative-Substrates slot is a list whose first member is a compound that was specified as a substrate; the remaining elements of the list are compounds that can serve as alternative substrates for the first compound.
Each value of the Alternative-Cofactors slot is a list whose first member is a compound that was specified as a cofactor or prosthetic group; the remaining elements of the list are compounds that can serve as alternatives for the first compound.
An annotation on a value for either of these slots is assumed to apply to each alternative substrate/cofactor listed in the value. If an annotation is intended to apply to only one such compound (or other subset), two (or more) values should be used instead, where the substrate is repeated as the first element of each value, and the alternative compounds are divided among the values according to the applicability of the annotations.
Reaction-Direction
This slot specifies the directionality of a reaction. This slot is used in slightly different ways in class Reactions and Enzymatic-Reactions. In class Enzymatic-Reactions, the slot specifies information about the direction of the reaction associated with the enzymatic-reaction, by the associated enzyme. That is, the directionality information refers only to the case in which the reaction is catalyzed by that enzyme, and may be influenced by the regulation of that enzyme.The slot is particularly important to fill for reactions that are not part of a pathway, because for such reactions, the direction cannot be determined automatically, whereas for reactions within a pathway, the direction can be inferred from the pathway context. This slot aids the user and software in inferring the direction in which the reaction typically occurs in physiological settings, relative to the direction in which the reaction is stored in the database. Possible values of this slot are
- REVERSIBLE: The reaction occurs in both directions in physiological settings.
- PHYSIOL-LEFT-TO-RIGHT, PHYSIOL-RIGHT-TO-LEFT: The reaction occurs in the specified direction in physiological settings, because of several possible factors including the energetics of the reaction, local concentrations of reactants and products, and the regulation of the enzyme or its expression.
- IRREVERSIBLE-LEFT-TO-RIGHT, IRREVERSIBLE-RIGHT-TO-LEFT: For all practical purposes, the reaction occurs only in the specified direction in physiological settings, because of chemical properties of the reaction.
- LEFT-TO-RIGHT, RIGHT-TO-LEFT: The reaction occurs in the specified direction in physiological settings, but it is unknown whether the reaction is considered irreversible.
Class Genes
Each frame in the class Genes describes a single gene, meaning a region of DNA that defines a coding region for one or more gene products. Multiple gene products may be produced because of modification of an RNA or protein.Left-End-Position, Right-End-Position
These slots encode the position of the left and right ends of the gene on the chromosome or plasmid on which the gene resides. "Left" means the end of the gene toward the coordinate-system origin (0). Therefore, the Left-End-Position is always less than the Right-End-Position.Centisome-Position
This slot lists the map position of this gene on the chromosome in centisome units (percentage length of the chromosome). The centisome-position values are computed automatically by Pathway Tools from the Left-End-Position slot. The value is a number between 0 and 100, inclusive.Transcription-Direction
This slot specifies the direction along the chromosome in which this gene is transcribed; allowable values are "+" and "-".Product
This slot holds the ID of a polypeptide or tRNA frame, which is the product of this gene. This slot may contain multiple values for two possible reasons: a given gene might be translated from more than one start codon, giving rise to products of different lengths; the product of the gene may undergo chemical modification. In the latter case, the gene lists all modified forms of the protein in its Product slot.Interrupted?
If True, indicates that the specified gene is interrupted, that is, has a premature stop codon.Class Organisms
The Organisms class is used in different ways in organism-specific PGDBs versus in multiorganism PGDBs such as MetaCyc. The next paragraph discusses what is common to both types of PGDBs. Subsequent paragraphs describe the differences.In all PGDBs, subclasses of Organisms define biological taxa, at all possible taxonomic levels. Class-subclass relationships between subclasses of Organisms describe their taxonomic relationships, since, for example, the class Bacteria includes as a subclass the class Alphaproteobacteria. Generally, most of the taxonomic groups under Organisms correspond to entries from the NCBI Taxonomy Database (which is stored in its entirety in a separate Ocelot KB). But in addition, to taxa from NCBI Taxonomy, a PGDB can contain subclasses for additional taxa that are not present in the NCBI Taxonomy.
Organism-specific PGDBs: In an organism-specific PGDB, the only frames that exist as children of Organisms are those frames needed to describe the taxonomic lineage of the organism described by the PGDB. An organism-specific PGDB contains a single instance frame that describes information about the PGDB itself. A parent class P of that instance must exist to describe the lowest taxonomic group defined for the organism. Additional parent classes exist as parents of P and children of Organisms that describe the other known taxonomic parents of P. No other children of Organisms exist in the PGDB.
Multiorganism PGDBs such as MetaCyc: Multiorganism PGDBs contain no instances of class Organisms, but only subclasses of this class. Those subclasses define each of the different organisms for which MetaCyc (for example) defines pathways and enzymes. For economy of storage, only those taxa (and their parent taxa) actually referenced in the PGDB are stored in the PGDB, so that only a subset of the NCBI Taxonomy is replicated in the PGDB. There is only one instance of Multi-Organism-Groupings that describes the properties of the PGDB.
PGDB-Authors
A list of the names of the authors of this DB. The names are displayed on a summary page for this organism. It is appropriate to suffix each name with the author's institution, for example, "John Doe, University of New Jersey". Use one slot value per author.PGDB-Copyright
The contents of this slot should be a copyright notice for this database, if one is desired. The copyright notice should preferably fit in one line because it will be printed at the bottom of every Web page served for this organism database by the Pathway Tools Web server. Example: "Copyright 1999 University of New Jersey."PGDB-Footer-Citation
The value of this slot should be a single literature citation, in the form of a string, such as "Bioinformatics 12:155 2002". This citation, if present, is printed at the bottom of each Web page served for this organism, within the following text: "Please cite XYZCyc as CITATION in publications resulting from its use."PGDB-Home-Page
The URL of a Web page describing this PGDB. Authors can use this page to provide more background information about the PGDB.PGDB-Name
The name of the database for this organism, when the database name is to be printed somewhere by Pathway Tools. Examples: "EcoCyc," "PlasmoCyc." The suffix "Cyc" is not required.PGDB-Unique-ID
An integer unique ID for this PGDB that differentiates it from other PGDBs. This ID is used to build unique IDs for frames that are newly created in this PGDB so that (a) when frames are copied among PGDBs, we know what PGDB the frame originated in, and (b) we can ensure that two frames in two different PGDBs that have the same ID do in fact refer to the same biological entity. The MetaCyc DB has a PGDB-Unique-ID of NIL; all other DBs should have a non-NIL value for this slot.Strain-Name
Specifies the strain name for the organism.Contact-Email
The email address of a person who serves at the primary contact for this PGDB, such as to receive questions or bug reports from users of the PGDB.Genome
A list of all replicons (chromosomes and plasmids) in the genome of the organism.Class Pathways
Frames in class Pathways encode metabolic and signaling pathways.Pathway-Interactions
This slot holds a comment that describes interactions between this pathway and other biochemical pathways, such as those pathways that supply an important precursor.Predecessors
This slot describes the linked reactions that compose the current pathway. Since pathways have a variety of topologies -- from linear to circular to tree structured -- pathways cannot be represented as simple sequences of reactions. A pathway is a list of reaction/predecessor pairs. That is, each value of this slot is of the form (reaction-ID pred-ID*) where reaction-ID is the key of a reaction in the pathway, and each pred-ID is the key of a reaction in the pathway that directly precedes the reaction-ID reaction. For example, to represent the combined pathway for tyrosine and phenylalanine synthesis, this predecessor list might be used:(chorismatemut-rxn) (prephenatedehydrat-rxn chorismatemut-rxn) (pheaminotrans-rxn prephenatedehydrat-rxn) (prephenatedehydrog-rxn chorismatemut-rxn) (tyraminotrans-rxn prephenatedehydrog-rxn)Figure 3. Pathway showing the Combined Synthesis of the Amino Acids tyrosine and phenylalanine from chorismate. Each reaction is labeled by its key in the EcoCyc DB. For example, the key for the reaction that converts prephenate to phenylpyruvate is prephenatedehydrog-rxn.
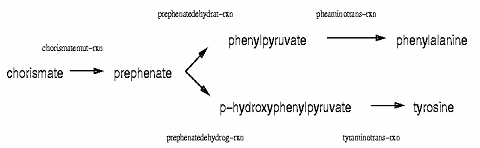
The first reaction in the pathway has no predecessor, so there is only one key within the first value. Since prephenate is a branch point in the pathway, two reactions in the pathway list the reaction that synthesizes prephenate as a predecessor.
Alternatively, any value for this slot can be another pathway key, which means that the current pathway inherits all the predecessor values of the indicated pathway. In other words, the current pathway is a superpathway of the indicated pathway. Thus, a more compact way of representing the combined pathway for tyrosine and phenylalanine synthesis would be to use the following predecessor list:
predecessors: tyrsyn, phesyn
In actuality, this latter representation is the preferred one and is required in order for the combined pathway to be determined to be a superpathway of either the tyrosine or phenylalanine (which of course should be the case). The advantage of specifying the predecessor list in this way (aside from being more compact and easy to read) is that if the subpathway is ever modified, the changes will automatically propagate to the superpathway.
Reaction-List
This slot lists all reactions in the current pathway, in no particular order.Hypothetical-Reactions
A list of reactions in this pathway that are considered hypothetical, probably because presence of the enzyme has not been demonstrated.Assume-Unique-Enzymes
By default it is assumed that all enzymes that can catalyze a reaction will do so in each pathway in which the reaction occurs. That default assumption is encoded by the default value of FALSE for this slot; when you want to assume that only one enzyme exists in the DB to catalyze every reaction in this pathway, this slot should be given the value TRUE.This slot can be used for consistency-checking purposes, that is, in a pathway for which this slot is TRUE, there should not be any reactions that are catalyzed by more than one reaction.
Enzyme-Use
By default it is assumed that all enzymes that can catalyze a reaction will do so in each pathway in which the reaction occurs. This slot is used in the case that this assumption does not hold, that is, if a reaction is catalyzed in a particular pathway by only a subset (or none) of the possible enzymes that are known to catalyze that reaction. Therefore, this slot can be used only when the value of the Assume-Unique-Enzymes slot is FALSE (because multiple enzymes catalyze some step in the pathway).The form of a value for the slot is (reaction-ID enzymatic-reaction-ID-1... enzymatic-reaction-ID-n). That is, each value specifies a reaction, and specifies the one or more enzymatic reactions that catalyze that reaction in this pathway. If no enzymatic reactions are specified, then none of the enzymes that are known to catalyze the reaction do so in this pathway.
For example, under aerobic conditions the oxidation of succinate to fumarate is catalyzed by succinate dehydrogenase in the forward direction, and, under anaerobic conditions, by fumarate reductase in the reverse direction. The TCA cycle is active only in aerobic conditions, so only succinate dehydrogenase is used in this pathway. This fact would be recorded as follows:
enzyme-use: (succ-fum-oxred-rxn succinate-oxn-enzrxn)
Enzymes-Not-Used
Proteins or protein-RNA complexes listed in this slot are those which would otherwise have been inferred to take part in the pathway or reaction, but which in reality do not. The protein may catalyze a reaction of the pathway in other circumstances, but not as part of the pathway (e.g. it may be not be in the same cellular compartment as the other components of the pathway, or it may not be expressed in situations when the pathway is active.).Primaries
When drawing a pathway, the Navigator software usually computes automatically which compounds are primaries (mains) and which compounds are secondaries (sides). Occasionally, the heuristics used are not sufficient to make the correct distinction, in which case you can specify primary compounds explicitly. This slot can contain the list of primary reactants, primary products, or both for a particular reaction in the pathway. Each value for this slot is of the form (reaction-ID (primary-reactant-ID-1 ... primary-reactant-ID-n) (primary-product-ID-1 ... primary-product-ID-n)), where an empty list in either the reactant or product position means that that information is not supplied and should be computed. An empty list in the product position can also be omitted completely.For example, in the purine synthesis pathway, we want to specify that the primary product for the final reaction in the pathway should be AMP and not fumarate. The primary reactants are still computed. The corresponding slot value would be
primaries: (ampsyn-rxn () (amp))
Species
This slot is used only in pathway frames in the MetaCyc DB, in which case the slot identifies the one or more species in which this pathway is known to occur experimentally.Disable Display
When the value is true, this slot disables display of the pathway drawing for a pathway.Super-Pathways
This slot lists direct super-pathways of a pathway.Sub-Pathways
This slot is the inverse of the Super-Pathways slot. It lists all the direct subpathways of a pathway.Pathway-Links
This slot indicates linkages among pathways in pathway drawings. Each value of this slot is a list of the form (cpd other-pwy*). The Navigator draws an arrow from the specified compound pointing to the names of the specified pathways, to note that the compound is also a substrate in those other pathways. If no other pathways are specified, then links are drawn to and from all other pathways that the compound is in (i.e., if the compound is produced by the current pathway, then links are drawn to all other pathways that consume it, and vice versa).Polymerization-Links
This slot controls drawing of polymerization relationships within a pathway. Each value of this slot is of the form (cpd-class product-rxn reactant-rxn). When both reactions are non-nil, an identity link is created between the polymer compound class cpd-class, a product of product-rxn, and the same compound class as a reactant of reactant-rxn. The Product-Name-Slot and Reactant-Name-Slot annotations specify which slot should be used to derive the compound label in product-rxn and reactant-rxn above, respectively, if one or both are omitted, Common-Name is assumed. Either reaction above may be nil; in this case, no identity link is created. This form is used solely in conjunction with one of the name-slot annotations to specify a name-slot other than Common-Name for a polymer compound class in a reaction of the pathway.Class-Instance-Links
Each value of this slot is a reaction in the pathway. Two annotations (in addition to the usual possibilities) are available on this slot: REACTANT-INSTANCES and PRODUCT-INSTANCES, whose values are compounds. If one of the reactants of the slot-value reaction is a class C and the REACTANT-INSTANCES are instances of C, then the instances are drawn as part of the pathway, with identity links to the class. The PRODUCT-INSTANCES are treated similarly.Layout-Advice
Each value of this slot is a dotted pair of the form (advice-keyword . advice), and represents some piece of advice to the automatic pathway layout code. Currently supported advice keywords are- :CYCLE-TOP-CPD: The advice is a compound key. In pathways containing a cycle, the cycle will be rotated so that the specified compound is positioned at twelve o'clock.
- :REVERSIBLE-RXNS: The advice is a list of reactions that should be drawn as reversible, even when the pathway is being drawn to show pathway flow (rather than true reversibility).
- :CASCADE-RXN-ORDERING: The advice is a list of reactions that form a partial order for reactions in a cascade pathway (i.e., the 2-component signaling pathways).
Class Polypeptides
Frames of class Polypeptides are monomers consisting of a single polypeptide chain.Gene
This slot contains a value that identifies the gene that encodes the polypeptide. When a polypeptide exists in two forms, modified and unmodified, both forms contain the same value in their Gene slots.Features
This slot links the polypeptide to any protein features that have been defined for it. When a polypeptide exists in multiple forms, each form will link to the same set of features.Splice-Form-Introns
This slot lists any introns that were spliced out of the gene in order to generate this polypeptide. Values of this slot are of the form (start-bp end-bp).Class Promoters
Frames in this class define transcription start sites.Absolute-Plus-1-Pos
The absolute base pair position of the transcription start site on the DNA strand.Binds-Sigma-Factor
This slot links to the one or more sigma factors that can bind to a promoter, thereby initiating transcription.Component-Of
This slot links to the transcription-unit(s) to which the promoter belongs.Minus-35-Left, Minus-35-Right, Minus-10-Left Minus-10-Right
These slots list chromosomal coordinates of the left and right ends of the -35 and -10 boxes associated with the promoter.Class Complexes
The class Complexes is subdivided into several subclasses.Frames of class Protein-Complexes are multimeric proteins composed of multiple subunits. The subunits of a protein complex may themselves be protein complexes, although eventually the subunits must bottom out as polypeptides.
Frames of class Protein-Small-Molecule-Complexes are the result of a protein (either a polypeptide or protein complex) binding with a small molecule ligand.
Frames of class Protein-RNA-Complexes are the result of one or more proteins forming a complex with one or more RNA molecules.
Frames of class Protein-DNA-Complexes are the result of a protein (or a complex that includes a protein, e.g., a protein complex or a complex of a protein and small-molecule ligand) binding with a segment of DNA. Examples of this include the binding of a transcription factor to a DNA binding site, or an RNA polymerase molecule binding to a promoter region of DNA in order to initiate transcription.
Components
This slot lists the subunits of a complex. The nature of the subunits depends on the type of complex. For a protein complex, each subunit is either a polypeptide or a protein complex; therefore, each slot value is the key of a polypeptide frame or a protein-complex frame. For other types of complexes, subunits may also include small-molecules, RNA molecules, or regions of DNA.The coefficient of each component of the protein complex is listed as an annotation of the component value under the label Coefficient.
Class Proteins
The class of all proteins is divided into two subclasses: protein complexes and polypeptides. A polypeptide is a single amino acid chain produced from a single gene. A protein complex is a multimeric aggregation of more than one polypeptide subunit. A protein complex may in some cases have another protein complex as a component. Many of the slots that are applicable to Proteins are also applicable to members of the RNAs class.Component-Of
This slot lists the complex(es) that this protein is a component of, if any, including protein complexes, protein-small-molecule complexes, protein-RNA complexes, and so on.DNA-Footprint-Size
For proteins that bind to DNA, the number of base pairs on the DNA strand that the binding protein covers.GO-Terms
Values of this slot are the Gene Ontology terms to which this object is annotated. Each value should be annotated with citations, including evidence codes.Locations
This slot describes the one or more cellular locations in which this protein is found. It's values are members of the CCO (Cell Component Ontology) class.Modified-Form
This slot points from the unmodified form of a protein to one or more chemically modified forms of that protein. For example, the slot might point from the unmodified form of a polypeptide (or a protein complex) to a phosphorylated form of that polypeptide (or protein complex).Molecular-Weight-KD
This computed slot lists the known molecular weight(s) of a macromolecule by taking the union of the slots Molecular-Weight-Seq and Molecular-Weight-Exp. Units: kilodaltons.Molecular-Weight-Seq
This slot lists the molecular weight of the protein complex or polypeptide, as derived from sequence data. Units: kilodaltons.Molecular-Weight-Exp
This slot lists the molecular weight of the protein complex or polypeptide, derived experimentally. Multiple values of this slot correspond to multiple experimental observations. Units: kilodaltons.pI
This slot lists the pI of the polypeptide.Regulates
For proteins that have regulatory activity (e.g. as transcription factors), this slot points to the Regulation frames that describe the regulation and link to the regulated entity.Species
This slot is used in proteins only in the MetaCyc DB, in which case it identifies the species in which the current protein is found.Unmodified-Form
This slot points from a chemically modified form of some protein, to the native unmodified form of that protein (e.g., from a phosphorylated form to the unphosphorylated form).Class Protein-Features
This class describes sites of interest (such as binding sites, modification sites, cleavage sites) on a polypeptide. Instances of this class define a region of interest on a polypeptide, plus, optionally, one or more states associated with the region. Different subclasses are used to specify single amino acid sites, linear regions, and regions involving noncontiguous segments of an amino-acid chain. For example, an instance F of this class could define an amino acid residue that can be phosphorylated, plus the fact that this residue can take on two possible states: PHOSPHORYLATED and UNPHOSPHORYLATED.The feature instance itself does not describe the state of a particular protein. Instead, we would represent the phosphorylated and unphosphorylated forms of a protein by creating two instances of class Polypeptides. Both of those instances would link to the same feature F via the Features slot. However, in the two proteins, F would be annotated differently to indicate the state of that feature. One protein would use an annotation label STATE with the value PHOSPHORYLATED to denote that the residue is phosphorylated, while the other would use the same annotation label STATE with the value UNPHOSPHORYLATED.
Attached-Group
For a binding feature, this slot lists the entity that binds to the protein feature -- it can be either an instance of Chemicals or of Protein-Features (e.g., in the case of crosslinks forming between two sites on the same or different polypeptide).Feature-Of
This slot points to the polypeptide frames with which this feature is associated (there could be more than one such frame, if all are different forms of the same protein, e.g., a modified and an unmodified form).Left-End-Position
For a feature that consists of a contiguous linear stretch of amino acids, this slot encodes the residue number of the leftmost amino acid, with number 1 referring to the N-terminal amino acid.Possible-Feature-States
For a given feature class, this slot describes the possible states available to instances of the class. For example, a feature that represents a binding site can have either a bound or unbound state. The list of possible states is stored at the class level as values for this slot. A particular instance F of the class (a specific feature of a specific protein) can then be labeled with this state information using the STATE annotation when F appears in the Features slot of the protein. For example, two forms of the same protein would link to the same feature F, but one form P1 would have the feature annotated label STATE and value BOUND, whereas the other form P2 would use the label STATE and value UNBOUND.Residue-Number
For a feature that consists of a single amino acid or some number of noncontiguous amino acids, this slot contains the numeric index or indices of the amino acid residue or residues that make up this site. Number 1 corresponds to the N-terminal amino acid.Right-End-Position
For a feature that consists of a contiguous linear stretch of amino acids, this slot encodes the residue number of the rightmost amino acid, relative to the start of the protein.Class Reactions
Frames within the Reactions class describe properties of a biochemical reaction independent of any enzyme or enzymes that catalyze that reaction. A reaction is a biochemical transformation that interconverts two sets of chemical compounds (which includes small metabolites, proteins, and DNA regions), and may translocate compounds from one cellular compartment to another. Most reactions are written in a conventional direction that has been assigned by the Enzyme Nomenclature Commission, but that direction may or may not be the predominate physiological direction of the reaction. Reaction substrates can include small-molecular-weight compounds (for metabolic reactions), proteins (such as in signaling pathways), and DNA sites (such as for reactions involving binding of transcription factors to DNA).Reactions are organized into two parallel ontologies. Most reaction frames will have one or more parents in both ontologies. The first classifies reactions by the nature of their substrates, for example, small-molecule reactions are reactions in which all substrates are small molecules, whereas protein reactions are reactions in which at least one substrate is a protein. The second ontology classifies reactions by conversion type. For example, chemical reactions are those in which a chemical transformation takes place, transport reactions are those in which a substrate is transported from one compartment to another (some reactions may be both transport reactions and chemical reactions if the substrate is chemically altered during transport), and binding reactions are those in which substrates weakly bind to each other to form a complex.
Two novel features of our conceptualization with respect to previous metabolic databases are to separate reactions from the enzymes that catalyze them, and to use the EC numbers defined by the International Union of Biochemistry and Molecular Biology (IUBMB) to uniquely identify reactions, not enzymes. (In database terms, the EC number is a key for the Reaction class.) The reason for this separation is that the catalyzes relationship between reactions and enzymes is many-to-many: a given enzyme might catalyze more than one reaction, and the same reaction might be catalyzed by more than one enzyme. Frames in the class Enzymatic-Reaction describe the association between an enzyme and a reaction. The entire EC taxonomy can be found under the Chemical-Reactions class.
You should always write transport reactions in the predominate direction in which the reaction occurs. Transport reactions are encoded by labeling substrates with their cellular compartment. For example, if a given substrate is transported from the periplasm to the cytoplasm, it would be labeled with "periplasm" as its compartment as a reactant, and with "cytoplasm" as its compartment as a product. The default compartment is the cytoplasm, so the cytoplasm label may be omitted. These labels are implemented as annotations in Ocelot.
EC-Number
This slot holds the EC (Enzyme Commission) number associated with the current reaction, if such a number has been assigned by the IUBMB. This slot is single valued.Official-EC?
The value of this slot is NO if the current reaction either was not defined at all by the Enzyme Commission, or if the current equation stored for that reaction is not the equation assigned by the EC (e.g., we have corrected the EC equation). Otherwise, the value is YES, which is the default inherited value.Left, Right
These slots hold the compounds from the left and right sides, respectively, of the reaction equation. Each value is either the key of a compound frame, or a string that names a compound (when the compound is not yet described within the DB as a frame). The terms reactant and product are not used because these terms may falsely imply the physiological direction of the reaction.The coefficient of each substrate, when that coefficient is not equal to 1, is stored as an annotation on the substrate value. The annotation label is COEFFICIENT.
The substrates of transport reactions are also described using the Left and Right slots. However, the values of these slots are annotated to indicate their compartments. For example, a transporter that moves succinate from the periplasm to the cytoplasm, accompanied by hydrolysis of ATP in the cytoplasm, would be described with succinate and ATP as the values of the Left slot, and with succinate, ADP, and Pi as the values of the Right slot. The succinate in the Left slot would be annotated with Periplasm under the label Compartment. The other substrates need not be annotated with a compartment because the default compartment is taken to be the cytoplasm.
Substrates
The value of this slot is computed automatically -- its values may not be changed by the user. The values of the slot are computed as the union of the values of the Left and Right slots.Enzymes-Not-Used
Proteins or protein-RNA complexes listed in this slot are those which would otherwise have been inferred to take part in the pathway or reaction, but which in reality do not. In other words, the protein may catalyze a general reaction with non-specific substrates, but is known not to catalyze this specific form of the reaction.DeltaG0
This slot contains the change in Gibbs free energy for the reaction in the direction the reaction is written.Spontaneous?
This slot is true in the case when this reaction occurs spontaneously, that is, it is not catalyzed by any enzyme.Species
This slot is used to indicate that a reaction is known to occur in an organism in the case where the enzyme that catalyzes the reaction is unknown. In such cases, the value for this slot in a given reaction would be the symbolic identifier of the species for the organism for the current PGDB.Reaction-Direction
This slot specifies the directionality of a reaction. This slot is used in slightly different ways in class Reactions and Enzymatic-Reactions. In class Reactions, the slot can be used to specify information about the direction in which the reaction occurs physiologically, and in addition the slot has a :Get-Method that computes a default value for the slot if no value is stored there. That method computes the default value by examining enzymatic-reactions attached to the reaction, and by examining pathways in which the reaction occurs, and combining the information it finds in those sources. If at least one source says the reaction occurs left-to-right, and at least one source says the reaction occurs right-to-left, it is deemed to be reversible.The slot is particularly important to fill for reactions that are not part of a pathway, because for such reactions, the direction cannot be determined automatically, whereas for reactions within a pathway, the direction can be inferred from the pathway context. This slot aids the user and software in inferring the direction in which the reaction typically occurs in physiological settings, relative to the direction in which the reaction is stored in the database. Possible values of this slot are
- REVERSIBLE: The reaction occurs in both directions in physiological settings.
- PHYSIOL-LEFT-TO-RIGHT, PHYSIOL-RIGHT-TO-LEFT: The reaction occurs in the specified direction in physiological settings, because of several possible factors including the energetics of the reaction, local concentrations of reactants and products, and the regulation of the enzyme or its expression.
- IRREVERSIBLE-LEFT-TO-RIGHT, IRREVERSIBLE-RIGHT-TO-LEFT: For all practical purposes, the reaction occurs only in the specified direction in physiological settings, because of chemical properties of the reaction.
- LEFT-TO-RIGHT, RIGHT-TO-LEFT: The reaction occurs in the specified direction in physiological settings, but it is unknown whether the reaction is considered irreversible.
Class Transcription-Units
Frames in this class encode transcription units, which are defined as a set of genes and associated control regions that produce a single transcript. Thus, there is a one-to-one correspondence between transcription start sites and transcription units. If a set of genes is controlled by multiple transcription start sites, then a PGDB should define multiple transcription-unit frames, one for each transcription start site.Components
The Components slot of a transcription unit lists the DNA segments within the transcription unit, including transcription start sites (class Promoters), Terminators, DNA-Binding-Sites, and Genes.Extent-Unknown?
The value of this slot should be True when it is not known to how many genes the transcription unit extends; that is, it is not known which is the last gene in the transcription unit.Class tRNAs
Frames of this class encode both charged and uncharged tRNAs.Anticodon
This slot contains a string as a single value, which lists the three letters that make up the anticodon bases on the tRNA. The direction in which the letters are listed is 5' to 3' with respect to the tRNA. This is the reverse of, and complementary to, the sequence of the recognized codons.Codons
This slot contains possibly multiple values as strings, which list the three letters that make up the base triplets recognized by the anticodon on the tRNA. The direction in which the letters are listed is 5' to 3' with respect to the coding strand of genes.Class Regulation
This class describes most forms of protein, RNA or activity regulation. Regulation can be either by a direct influence on the protein's activity (e.g. allosteric inhibition of an enzyme) or by influencing the quantity of active protein available (e.g. by inducing or blocking its transcription or translation). The one form of regulation that is not covered by this class is when the quantity of a protein is regulated as a result of chemical or binding reactions that either produce or consume the active form of a protein -- these are represented as Reactions instead. There can be some ambiguity as to what should be represented as a reaction and what should be represented as a regulation event. In general, an event that can be represented as a reaction should be when a) there is sufficiently detailed information known to model it as a reaction, b) both reactants and products exist as stable, independent entities, and c) our schema supports referring to both reactant and product of the reaction independently and there is some justification for wanting to go down to that level of detail. For example, a transcription factor bound to a small molecule will generally have a different activity than the unbound transcription factor. This could be represented either as the reaction TF + x → TF-x or as a regulation event in which x activates or inhibits the activity of TF. However, because both TF and TF-x are stable molecules which can potentially regulate different transcription units (not all will, but some do), or TF could bind another small molecule y and regulate yet another set of transcription units, we prefer to model this kind of interaction as a reaction when the data is available. On the other hand, an enzyme binding to some inhibitor could also be represented as a reaction, but since there is rarely any reason to refer to the enzyme-inhibitor complex outside of the context of the reaction the enzyme catalyzes, we choose instead to model these events as regulation events in which the inhibitor regulates the activity of the enzyme.Instances of this class represent a one-to-one mapping between regulator and regulated-entity (i.e. an entity may regulate many processes, or a process may be regulated by many entities, but each one requires its own instance of Regulation to represent it)
Some of the slots listed below are applicable only to certain subclasses of Regulation.
Associated-Binding-Site
This slot is applicable to regulation of transcription or translation in which an entity (protein, small-molecule or RNA) binds to DNA or the mRNA transcript. Its values are instances of either DNA-Binding-Sites or mRNA-Binding-Sites, depending on the type of regulation.Mechanism
This slot optionally contains a keyword which describes the mechanism of the regulation. Appropriate possible values will vary depending on the particular subclass of regulation. Some subclasses will not use this slot at all.Mode
This slot specifies whether the regulator activates or inhibits the regulated-entity. Possible values are:- "+" -- The regulator activates or increases quantity or activity of the regulated-entity (an exception is transcription attenuation, in which even though the regulated-entity is a terminator object, "+" means activation of transcription of the downstream genes rather than of the terminator).
- "-" -- The regulator inhibits or decreases quantity or activity of the regulated-entity (with the same caveat about transcription attenuation as above)..