Search
Genome
Metabolism

|
|
Guide to MetaCyc
Contents
2 MetaCyc Overview
4 MetaCyc Curation
5 Taxonomic Designations for Pathways
6 Release Process, Frequency, and History
10 Comparison of MetaCyc to other Pathway Databases
11 The MetaCyc Team
12 Submitting Pathways for Incorporation into MetaCyc
13 MetaCyc Publications
1 IntroductionThis guide provides additional information on the MetaCyc database (DB) beyond that found in other MetaCyc publications [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], to help users of the database understand its contents in more depth. MetaCyc is a member of the BioCyc collection of Pathway/Genome Databases. In contrast to all other members of that collection, which are organism-specific DBs, MetaCyc is a multiorganism DB. The other BioCyc databases describe the metabolic network and genome of a single organism, and mix experimentally determined pathways with computationally predicted pathways. MetaCyc contains experimentally elucidated pathways only; one goal of the MetaCyc project is for MetaCyc to contain a representative example of as many experimentally-determined metabolic pathways as possible. MetaCyc does not seek to model the complete metabolism of any particular organism, which is the role of individual BioCyc DBs. Instead, MetaCyc serves as a general reference on metabolic pathways and enzymes. MetaCyc is also used as a high-quality reference DB for predicting metabolic pathways in other organisms. Scientists use MetaCyc for a broad range of tasks, such as finding enzymes for metabolic engineering projects, learning about the possible metabolic fates of specific compounds, identifying metabolites based on mass spectrometry data, or finding a comprehensive description for complex pathways. For questions that require information about the complete genome, proteome, or metabolic network of a particular organism, users are advised to consult the appropriate organism-specific PGDB. For example, MetaCyc contains 21 pathways and 112 enzymes that have been experimentally studied in Staphylococcus aureus. In contrast, the BioCyc Staphylococcus aureus database contains 201 pathways (most of which are computationally predicted), plus the entire genome and proteome of that strain.
2 MetaCyc OverviewMetaCyc is a database of non-redundant, experimentally elucidated metabolic pathways and enzymes. It also contains reactions, chemical compounds, and genes. It stores predominantly qualitative information rather than quantitative data, although it does contain some quantitative data such as enzyme kinetics data. “MetaCyc” is pronounced “met-a-sike”. It sounds like “encyclopedia”. A unique property of MetaCyc is that it is curated[def] from the scientific experimental literature according to an extensive process [4], such that:
2.1 MotivationsThe MetaCyc mission is to serve a broad community of researchers from genetics, molecular biology, microbiology, biochemistry, genomics, metabolomics, bioinformatics, metabolic engineering, and systems biology in support of the following tasks:
2.2 Database ContentsMetaCyc stores pathways involved in both [Primary metabolism] and [Secondary metabolism]. MetaCyc’s metabolites, enzymes, enzyme complexes, and genes are not limited to those associated with these pathways; the database contains many enzymes and reactions not associated with pathways. MetaCyc is extensively linked to other biological databases [8] including protein and nucleic-acid sequence databases and chemical compound databases. While MetaCyc itself does not contain protein or gene sequence data, protein sequences are easily retrievable for MetaCyc enzymes that have a link to UniProt. To retrieve this information, Click on the "Show Sequence at UniProt" command in the Operations menu.
2.3 Query and VisualizationMetaCyc data can be browsed and queried in multiple ways. For pathways, proteins, reactions and compounds, the MetaCyc site supports:
Extending information to other databases: every object in MetaCyc enables quick searching for it in a specific organism or a set of organisms via the Operations menu (right side) commands Show This Object in Another Database and Search for this Object in Multiple Databases. Comparison features combine MetaCyc with other BioCyc databases to provide additional ways for viewing data. Examples for Cross-Species comparisons include:
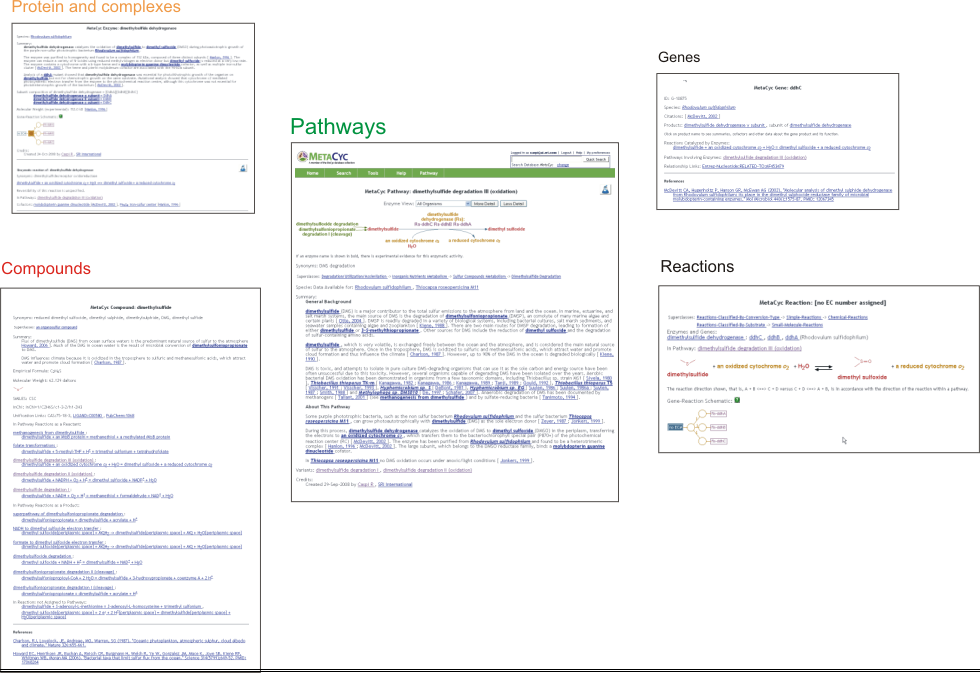
2.4 The MetaCyc Data UniverseMetaCyc inter-relates information about pathways, reactions, compounds, proteins, and genes. Each object name is typically a hyperlink to the page describing that object. For example, while looking at a pathway page, clicking on a compound, reaction arrow, protein name, or gene name will navigate to those object’s pages, making it extremely easy for the user to navigate among the different database’s objects.
2.5 Linking to MetaCycUsers are encouraged to link their Web site or application to MetaCyc as described here.
2.6 DevelopmentSince its beginning in 1998, MetaCyc’s data have been gathered from a variety of literature and on-line sources. MetaCyc is currently curated by a single full-time curator at SRI International. Some of the data in MetaCyc have been curated via collaborative projects between SRI International and the Marine Biological Laboratory, the Carnegie Institution’s Department of Plant Biology, and the Boyce Thomson Institute for Plant Research.
2.7 Underlying SoftwareCuration and navigation of MetaCyc is performed using the Pathway Tools platform — which can be obtained here.
3 MetaCyc AvailabilityMetaCyc is available via a BioCyc subscription in several different forms to facilitate different uses of the data:
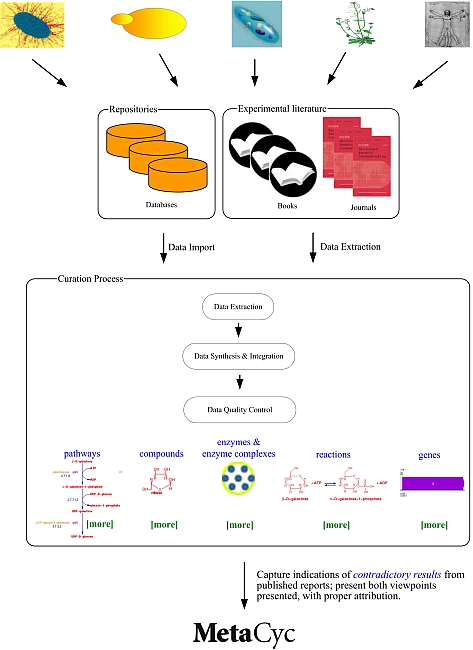
4 MetaCyc CurationCuration is the process of manually refining and updating a bioinformatics database. The MetaCyc project uses a literature-based curation approach in which database contents are extracted in a step-wise manner from evidence in the experimental literature, as depicted below. The curation procedures that MetaCyc curators follow are described in the Curator’s Guide to Pathway/Genome Databases. MetaCyc data are derived from primary literature, review articles, patent applications, and from external databases. For certain organisms, some of the data within MetaCyc have been directly imported from other databases which we consider to be the authoritative sources of data on those organisms:
4.1 Information Types Captured During the MetaCyc Curation ProcessNote that not all objects contain all of the information types listed here; rather, this list describes the potential types of information for each object type.
4.1.1 PathwaysPathways include a mini-review summary that usually includes:
Other collected data include:
4.1.2 Reactions
4.1.3 Enzymes and Enzyme ComplexesMost enzymes include a mini-review summary that covers:
Other collected data:
4.1.4 Genes
4.1.5 Compounds
Compound structures are obtained either from the primary literature or from public compound structure databases such as ChEBI and ChemSpider. The structures are edited using the Marvin software to provide a consistent look and to reflect the most prevalent protonation state at pH 7.3. For more information about protonation, see Reaction Balancing and Protonation State in BioCyc at the Guide to The BioCyc Database Collection. We would like to express our gratitude to Chemaxon for granting us a free license to their Marvin software.
5 Taxonomic Designations for PathwaysMetaCyc pathways are labeled with the name of one or more taxa in which wet-lab experiments have indicated that the pathway is present. These taxonomic designations are present on the pathway page in a line labeled “Some taxa known to possess this pathway include,” and include species names, species and strain names, and occasionally names of higher taxa such as genus names, e.g., Pseudomonas. When a high-level taxon, such as a genus, is present as a pathway label, the interpretation is that experimental evidence suggests that the pathway is present in all members of that taxon. The “number of organisms” row in the MetaCyc statistics indicates the total number of different organisms that are referenced in the database. These could be listed in the taxonomic designations of pathways, but could also be references by enzymes that do not participate in pathways, or simply be mentioned in pathway/enzyme summaries. There is wide variation in how many pathways a given taxon contributes to MetaCyc, with some taxa contributing only a single pathway, and other taxa contributing more than 100 pathways. The taxonomic distribution of MetaCyc pathways is summarized here: [Pathway Taxonomic Distribution] . To query MetaCyc pathways by species:
MetaCyc pathway pages also specify an “Expected taxonomic range,” which lists the taxonomic groups in which this pathway is expected to occur. This information is useful for pathway prediction.
6 Release Process, Frequency, and HistoryNew versions of MetaCyc are released 3–4 times per year.
A detailed history of the enhancements to MetaCyc in each MetaCyc release is available here. This page also contains statistics on the changes in the content of MetaCyc over time.
6.1 MetaCyc Release ProceduresThe MetaCyc staff perform the following operations as part of each MetaCyc major release (some are performed for minor releases as well):
7 BLASTing Against MetaCycA common early step in performing pathway analysis of genomes and metagenomes is to associate protein sequences to MetaCyc reactions. The Pathway Tools software infers such associations by using EC numbers, enzyme names, and Gene Ontology terms within protein annotations. Such annotations might be inferred using a variety of sequence-analysis methods.
To aid researchers in associating sequences to MetaCyc reactions, MetaCyc enzymes
that have a link to UniProt contain protein sequence information. It is possible
to perform BLAST searches against MetaCyc proteins with sequence information
using the "BLAST Search" command under the Search menu. In addition, each release
of MetaCyc includes a file that associates MetaCyc reaction IDs with the
UniProt identifiers of enzymes known to catalyze those reactions. Note that
not all MetaCyc reactions have EC numbers (because many enzymes have not yet
been assigned EC numbers), therefore EC numbers are not a comprehensive mechanism
for associating sequences to reactions. The file is called
8 Database LinksMetaCyc contains links to many other bioinformatics DBs. Some MetaCyc links are “unification links”, meaning they are links from an object in MetaCyc to an object in another DB that represents the same biological object. Other links are “relationship links”, meaning that they are links from an object in MetaCyc to an object in another DB that represents a related object, such as a link from a MetaCyc reaction to a PIR protein that catalyzes that reaction. Note that not all objects contain links to all of the databases listed here; rather, this list describes the potential links for each object type. The following types of MetaCyc objects contain links to the following databases.
9 Data SourcesMetaCyc incorporates information that was obtained from the following sources:
10 Comparison of MetaCyc to other Pathway Databases10.1 KEGGA detailed comparison of KEGG and BioCyc was posted here in 2023: https://bioinformatics.ai.sri.com/biocyc/kegg-biocyc-comparison.pdf. Another comparison of KEGG and MetaCyc was published in 2013 [15]. KEGG contains two types of pathways: maps and modules.
MetaCyc pathways (and KEGG modules) are closer to true biological pathways than are KEGG maps because they attempt to model individual biological pathways from individual organisms. KEGG maps are typically 3–4 times larger than are KEGG modules and MetaCyc pathways because of the chimeric nature of KEGG maps. For example, KEGG map MAP00270 called “cysteine and methionine metabolism” combines pathways for the biosynthesis of L-methionine, L-cysteine, L-homocysteine, L-homoserine, ethylene, and methanethiol; for degradation of L-serine, L-cysteine, L-methionine, sulfolactate, S-methyl-5’-thioadenosine, and S-methyl-5-thio-alpha-D-ribose 1-phosphate; for homocysteine and cysteine interconversion; and for methionine salvage. Although KEGG maps (and MetaCyc superpathways) are useful in showing how individual pathways connect and in presenting the larger biochemical context in which a pathway operates, they are not suitable for many types of analyses. For example, using KEGG maps, a program for predicting the metabolic pathways of an organism could not predict methionine biosynthesis independently of ethylene biosynthesis, although many organisms do not produce the latter, because those two separate processes are fused into one KEGG map. Similarly, if a program for enrichment analysis of transcriptomics data detects enrichment of MAP00270, we would not know which actual pathway was in fact enriched: methionine biosynthesis or ethylene biosynthesis. For that matter, MAP00270 could receive a high enrichment score because of differential expression of genes within multiple pathways within that map when in fact no individual pathway was highly enriched. And because maps are so large, a large number of genes must be differentially expressed for a map to obtain a high enrichment score. The smaller pathways in MetaCyc (and KEGG modules) are advantageous for several reasons: they correspond to a single biological function, the enzymes participating in them are usually regulated as a unit, and they tend to be conserved through evolution. MetaCyc pathway diagrams have several advantages over KEGG modules: MetaCyc diagrams include full chemical compound names and enzyme names (KEGG module diagrams contain only unintelligible identifiers), and MetaCyc diagrams can show the full chemical structures for substrates (the user can select the level of detail shown by choosing to turn on or off the display of structures and/or enzyme names), and can depict regulatory influences on the pathway. Maps and superpathways are useful in showing how individual pathways connect, and in presenting the larger biochemical context in which a pathway operates. MetaCyc pathways can be displayed at multiple detail levels, such as showing chemical structures for substrates. In addition, all MetaCyc pathway diagrams include chemical names and enzyme names; KEGG module diagrams contain unintelligible identifiers only. MetaCyc records separately the different pathway variants that have been observed in different organisms. For example, MetaCyc contains six different pathway variants for synthesizing L-lysine. KEGG does not identify pathway variants. Within the large maps defined by KEGG, it is impossible for the user to tell which subnetworks correspond to distinct biological units, nor in which species these units have been elucidated experimentally. MetaCyc curators author extensive mini-review summaries that describe most pathways and enzymes. KEGG contains short summaries for approximately half of its pathway maps. MetaCyc pathways are labeled with the name(s) of some of the species in which the presence of those pathways has been experimentally determined, whereas such information is irrelevant for KEGG maps since they are chimeric. Pathways in MetaCyc and in other BioCyc PGDBs contain evidence codes that indicate whether experimental or computational evidence supports the presence of the pathway in that organism; KEGG does not use evidence codes. MetaCyc proteins contain enzyme properties such as subunit composition, substrate specificity, cofactor requirements, activators, and inhibitors. KEGG has only cofactor data. However, because those data are associated with KEGG reactions rather than with KEGG enzymes, it is difficult to be sure for which proteins from which species the cofactor requirement was experimentally elucidated. MetaCyc compounds include calculated Gibbs free energies of formation, SMILES, and InChIs, which are missing from KEGG compounds. Comparing MetaCyc version 27.1 (August 2023) with KEGG version 107.0+ (September 2023), we find that MetaCyc contained contained 3,128 pathways (7.0 times more than KEGG), compared to the 445 metabolic modules in KEGG. MetaCyc contained 18,819 (1.6 times more) reactions, compared to 11,964 in KEGG, and MetaCyc contains 19,173 metabolites compared to 19,136 in KEGG. MetaCyc contains 10,618 textbook-equivalent pages of mini-review summaries for enzymes and pathways versus 1,002 textbook-equivalent pages for KEGG. MetaCyc cites 76,000 publications, from which its curation was drawn (we do not know the equivalent number for KEGG). BioCyc Organism-Specific PGDBs Compared to KEGG Species Views of Pathway Maps KEGG version 107.0+ contained 9,313 organisms whereas BioCyc version 27.1 contained 20,042 organism databases (2.2 times more). Sixty nine of the BioCyc databases are designated as Tier 1 or Tier 2, meaning they have undergone some amount of manual curation. BioCyc curation was drawn from 146,000 publications compared to 71,301 publications cited by KEGG. In some cases, BioCyc databases received several person-years of curation (e.g., for Arabidopsis thaliana) or even person-decades (e.g., for EcoCyc and MetaCyc) of curation. In contrast, KEGG curates only its reference pathway maps and modules; it does not curate organism-specific views of those data, which are generated computationally. Manually curated databases have significant of advantages, including higher accuracy and richer information. Curators remove incorrectly predicted pathways and add pathways that should have been predicted. Curators also add additional information from the literature that often results in modifying the original annotation, and add content such as mini-review summaries, evidence codes, literature citations, and enzyme properties. Pathway Tools Software Compared to KEGG Software The Pathway Tools software that underlies MetaCyc and BioCyc is more advanced than the KEGG software in many respects. Pathway Tools can be installed locally at your site, and many of its operations are available via the BioCyc website.
10.2 EAWAG Biocatalysis/Biodegradation DatabaseThe Biocatalysis/Biodegradation Database was developed by the University of Minnesota and used to be known as UM-BBD. The database contains information on microbial biocatalytic reactions and biodegradation pathways for chemicals largely considered to be potential environmental pollutants. The data is now hosted at the Swiss Federal Institute of Aquatic Science and Technology and the database is known as the EAWAG Biocatalysis/Biodegradation Database. The web site states that the database has not been updated since 2016. As of January 18, 2023 the database contained 219 pathways and 993 enzymes from 543 microorganisms. Pathways were curated from the biomedical literature and some contain significant comments and literature citations.
10.3 ReactomeReactome is a curated database of biological processes in humans and a few other organisms. It covers biological pathways ranging from the basic processes of metabolism to high-level processes such as hormonal signaling. Reactome information is curated form the literature, and includes significant comments and literature citations. Reactome contains far fewer metabolic pathways than does MetaCyc, and because most Reactome pathways are curated based on human biology — Reactome does not have the taxonomic breadth of MetaCyc, although Reactome pathways have been computationally projected to a number of model organisms.
11 The MetaCyc TeamThis section summarizes the many past and present contributors to the MetaCyc project.
11.1 Current ContributorsRoles: Curation of pathways, software development, Website operations
11.2 Past Contributors
12 Submitting Pathways for Incorporation into MetaCycWe would be happy to incorporate pathways created by other scientists into the database. If you are a Pathway Tools user and have created a pathway that fits our criteria, please send it to us. When we include externally submitted pathways in MetaCyc, we credit the contribution in the MetaCyc release notes, and if you wish, your name and your institution will appear on the pathway page. In addition, by submitting pathways to MetaCyc you not only add to MetaCyc, but you increase the power of the PathoLogic metabolic-pathway prediction software. PathoLogic recognizes MetaCyc pathways in genome sequence data, and is now in use by hundreds of groups worldwide. If you would like to submit a pathway for inclusion in a future release of MetaCyc, please make sure that you curate the pathway following these guidelines:
For examples of pathways that have been curated based on these guidelines, please see:
Further information can be found in the Curator’s Guide for Pathway/Genome Databases.
12.1 How to Ensure that You and Your Organization Receive the Appropriate CreditPathway Tools includes an author crediting system that can attach author and organization credentials to individual pathways. We recommend that prior to creating new objects in the PGDB you should create an Organization frame for your institute and an Author frame for yourself. This way, items that you create afterwards will be associated with these frames, providing you with the credit that you deserve. This credit information would be retained upon exporting the pathways and importing them into MetaCyc. It is also possible to add credit information to older pathways that were created prior to the creation of your author frame, through the Pathway Info Editor. Detailed instructions on how to create organization and author frames are found in the pathway Tools user manual, in the section “Creating Author Frames”.
12.2 How to Send Pathways to MetaCycPathways should be exported into a text file, which can be emailed to us at: . The procedure for exporting a pathways is:
Please indicate if you would like your name and/or affiliation to appear on the pathway and enzyme pages. 13 MetaCyc PublicationsIf you use MetaCyc in your research, we ask that you cite the following publication:
[MetaCyc20] Caspi, R., Billington, Keseler, I.M., Kothari, A.,
Krummenacker, M., Midford, P.E., Ong, Q., Paley, S., Subhraveti,
P. and Karp, P.D. (2020)
13.1 Additional Publications
[MetaCyc18] Caspi, R., Billington, Fulcher, C.A., Keseler, I.M., Kothari, A.,
Krummenacker, M., Latendresse, M., Midford, P.E., Ong, Q., Paley, S., Subhraveti, P. and Karp, P.D. (2018)
[MetaCyc16] Caspi, R., Billington, R., Ferrer, L., Foerster, H., Fulcher, C.A., Keseler, I.M., Kothari, A.,
Krummenacker, M., Latendresse, M., Mueller, L.A., Ong, Q., Paley, S., Subhraveti, P., Weaver, D.S. and Karp, P.D.(2016)
[MetaCyc14] Caspi, R., Altman, T., Billington, R., Dreher, K., Foerster, H, Fulcher, C.A., Holland, T.A., Keseler, I.M., Kothari, A., Kubo, A., Krummenacker, M., Latendresse, M., Mueller, L.A., Ong, Q., Paley, S., Subhraveti, P., Weaver, D.S., Weerasinghe, D., Zhang, P., and Karp, P.D.(2014)
[MetaCyc13] Altman, T., Travers, M., Kothari, A., Caspi, R. and Karp, P.D.
A systematic comparison of the MetaCyc and KEGG pathway
databases
[Curation13] Caspi, R., Dreher, K, and Karp, P.D.
The challenge of constructing, classifying and representing metabolic pathways
[MetaCyc12] Caspi, R., Altman, T., Dreher, K., Fulcher, C.A., Subhraveti, P., Keseler, I.M., Kothari, A., Krummenacker, M., Latendresse, M.,
Mueller, L.A., Ong, Q., Paley, S., Pujar, A., Shearer, A.G., Travers, M., Weerasinghe, D., Zhang, P., and Karp, P.D. (2012)
[MetaCyc11] Karp, P.D., and Caspi, R.,
A survey of metabolic databases emphasizing the MetaCyc family
[MetaCyc10] Caspi, R., Altman, T., Dale, J.M., Dreher, K., Fulcher, C.A., Gilham, F., Kaipa, P., Karthikeyan, A.S., Kothari, A., Krummenacker, M., Latendresse, M., Mueller, L.A., Paley, S., Popescu, L., Pujar, A., Shearer, A., Zhang, P. and Karp, P.D. (2010)
[MetaCyc08] Caspi, R., Foerster, H., Fulcher, C.A., Kaipa, P., Krummenacker, M.,
Latendresse, M., Paley, S., Rhee, S.Y., Shearer, A., Tissier, C.,
Walk, T.C., Zhang, P. and Karp, P.D. (2008)
[MetaCyc06] Caspi, R., Foerster, H., Fulcher, C.A., Hopkinson, R.,
Ingraham, J., Kaipa, P., Krummenacker, M., Paley, S., Pick, J.,
Rhee, S.Y., Tissier, C., Zhang, P. and Karp, P.D. (2006)
[MetaCyc04]
Krieger, C.J., Zhang, P., Mueller, L.A., Wang, A., Paley, S.,
Arnaud, M., Pick, J., Rhee, S.Y., and Karp, P.D. (2004)
[MetaCyc03]
Karp, P.D. (2003)
[MetaCyc02]
Karp, P.D., Riley, M., Paley, S. and Pellegrini-Toole, A. (2002)
[MetaCyc00] Karp, P.D., Riley, M., Saier, M., Paulsen, I.T., Paley, S., and Pellegrini-Toole, A. (2000) See also the BioCyc Publications Page.
14 How to Learn More
References
|